Batch Normalization 到底要放在激勵函數之前還是之後呢?這是之前我在自己練習規劃架構時遇到的問題,我把這個問題拿去網路上查時,發現也有不少人在討論它,這篇 reddit 的討論 [D] Batch Normalization before or after ReLU? 我覺得蠻有意思的,放前面跟放後面都各自有論文推崇。
理論上 BN 是用來正規化輸出的結果,如果今天放在 ReLU 之後,有些負的輸出會變成0,那麼 BN 的正規化是不是就會有偏頗?所以我自己也是習慣把 BN 放在激勵函數前,先將 CNN/Dense 的輸出正規化之後再經過激勵函數。
但是也有不少的實驗結果得到把 BN 放在激勵函數之前,讓模型學到比激勵函數之後有更好的準確度。因此,今天就決定來做這個小實驗,比較兩者的差異。
實驗一:Layer -> BN -> Act
def bottleneck(net, filters, out_ch, strides, shortcut=True, zero_pad=False):
padding = 'valid' if zero_pad else 'same'
shortcut_net = net
net = tf.keras.layers.Conv2D(filters * 6, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
if zero_pad:
net = tf.keras.layers.ZeroPadding2D(padding=((0, 1), (0, 1)))(net)
net = tf.keras.layers.DepthwiseConv2D(3, strides=strides, use_bias=False, padding=padding)(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.Conv2D(out_ch, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
if shortcut:
net = tf.keras.layers.Add()([net, shortcut_net])
return net
def get_mobilenetV2_before_act(shape):
input_node = tf.keras.layers.Input(shape=shape)
net = tf.keras.layers.Conv2D(32, 3, (2, 2), use_bias=False, padding='same')(input_node)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.DepthwiseConv2D(3, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.Conv2D(16, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = bottleneck(net, 16, 24, (2, 2), shortcut=False, zero_pad=True) # block_1
net = bottleneck(net, 24, 24, (1, 1), shortcut=True) # block_2
net = bottleneck(net, 24, 32, (2, 2), shortcut=False, zero_pad=True) # block_3
net = bottleneck(net, 32, 32, (1, 1), shortcut=True) # block_4
net = bottleneck(net, 32, 32, (1, 1), shortcut=True) # block_5
net = bottleneck(net, 32, 64, (2, 2), shortcut=False, zero_pad=True) # block_6
net = bottleneck(net, 64, 64, (1, 1), shortcut=True) # block_7
net = bottleneck(net, 64, 64, (1, 1), shortcut=True) # block_8
net = bottleneck(net, 64, 64, (1, 1), shortcut=True) # block_9
net = bottleneck(net, 64, 96, (1, 1), shortcut=False) # block_10
net = bottleneck(net, 96, 96, (1, 1), shortcut=True) # block_11
net = bottleneck(net, 96, 96, (1, 1), shortcut=True) # block_12
net = bottleneck(net, 96, 160, (2, 2), shortcut=False, zero_pad=True) # block_13
net = bottleneck(net, 160, 160, (1, 1), shortcut=True) # block_14
net = bottleneck(net, 160, 160, (1, 1), shortcut=True) # block_15
net = bottleneck(net, 160, 320, (1, 1), shortcut=False) # block_16
net = tf.keras.layers.Conv2D(1280, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
return input_node, net
input_node, net = get_mobilenetV2_before_act((224,224,3))
net = tf.keras.layers.GlobalAveragePooling2D()(net)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[input_node], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
輸出:
Epoch 51/100
loss: 0.0194 - sparse_categorical_accuracy: 0.9942 - val_loss: 0.8054 - val_sparse_categorical_accuracy: 0.8281
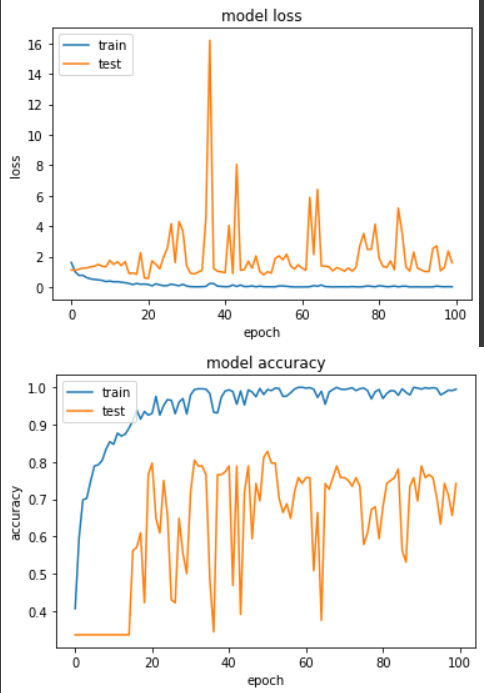
實驗二:Layer -> Act -> BN
def bottleneck(net, filters, out_ch, strides, shortcut=True, zero_pad=False):
padding = 'valid' if zero_pad else 'same'
shortcut_net = net
net = tf.keras.layers.Conv2D(filters * 6, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.BatchNormalization()(net)
if zero_pad:
net = tf.keras.layers.ZeroPadding2D(padding=((0, 1), (0, 1)))(net)
net = tf.keras.layers.DepthwiseConv2D(3, strides=strides, use_bias=False, padding=padding)(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.Conv2D(out_ch, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
if shortcut:
net = tf.keras.layers.Add()([net, shortcut_net])
return net
def get_mobilenetV2_after_act(shape):
input_node = tf.keras.layers.Input(shape=shape)
net = tf.keras.layers.Conv2D(32, 3, (2, 2), use_bias=False, padding='same')(input_node)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.DepthwiseConv2D(3, use_bias=False, padding='same')(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.Conv2D(16, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = bottleneck(net, 16, 24, (2, 2), shortcut=False, zero_pad=True) # block_1
net = bottleneck(net, 24, 24, (1, 1), shortcut=True) # block_2
net = bottleneck(net, 24, 32, (2, 2), shortcut=False, zero_pad=True) # block_3
net = bottleneck(net, 32, 32, (1, 1), shortcut=True) # block_4
net = bottleneck(net, 32, 32, (1, 1), shortcut=True) # block_5
net = bottleneck(net, 32, 64, (2, 2), shortcut=False, zero_pad=True) # block_6
net = bottleneck(net, 64, 64, (1, 1), shortcut=True) # block_7
net = bottleneck(net, 64, 64, (1, 1), shortcut=True) # block_8
net = bottleneck(net, 64, 64, (1, 1), shortcut=True) # block_9
net = bottleneck(net, 64, 96, (1, 1), shortcut=False) # block_10
net = bottleneck(net, 96, 96, (1, 1), shortcut=True) # block_11
net = bottleneck(net, 96, 96, (1, 1), shortcut=True) # block_12
net = bottleneck(net, 96, 160, (2, 2), shortcut=False, zero_pad=True) # block_13
net = bottleneck(net, 160, 160, (1, 1), shortcut=True) # block_14
net = bottleneck(net, 160, 160, (1, 1), shortcut=True) # block_15
net = bottleneck(net, 160, 320, (1, 1), shortcut=False) # block_16
net = tf.keras.layers.Conv2D(1280, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.BatchNormalization()(net)
return input_node, net
input_node, net = get_mobilenetV2_after_act((224,224,3))
net = tf.keras.layers.GlobalAveragePooling2D()(net)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[input_node], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
輸出:
Epoch 67/100
loss: 0.0035 - sparse_categorical_accuracy: 1.0000 - val_loss: 1.0461 - val_sparse_categorical_accuracy: 0.8203
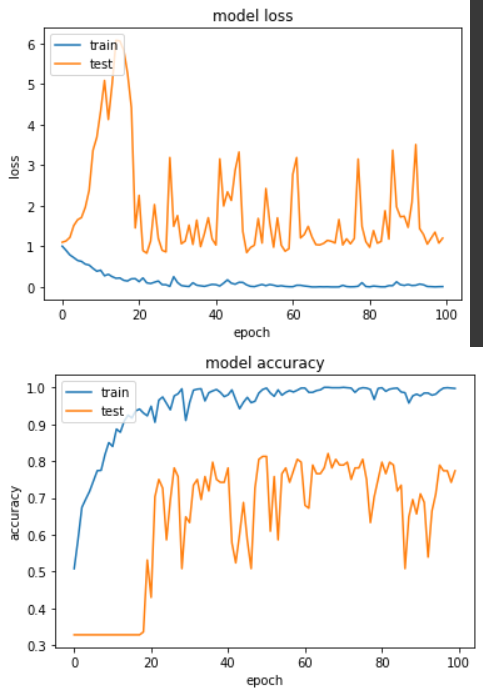
實驗結果顯示,兩者的最佳準確度差不多,看來儘管把 BN 放在激勵函數之後,還是可以讓模型收斂。我自己實務上仍是傾像於把 BN 放在激勵函數之前(實驗一),讓 BN 去學習 CNN/Dense 的權重。

